Learning Transferable Visual Models From Natural Language Supervision
Give a summary of the approach used in CLIP.
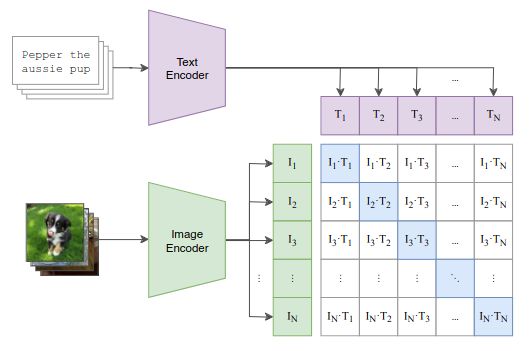 Given a batch of (image, text) pairs, CLIP learns a multi-model embedding space by jointly training an image encoder and text encoder to maximize the cosine similarity of the image and text embeddings of the correct pairs while minimizing the cosine similarity of the incorrect pairs. (It is optimized using a symmetric cross entropy loss over these similarity scores)
Given a batch of (image, text) pairs, CLIP learns a multi-model embedding space by jointly training an image encoder and text encoder to maximize the cosine similarity of the image and text embeddings of the correct pairs while minimizing the cosine similarity of the incorrect pairs. (It is optimized using a symmetric cross entropy loss over these similarity scores)
How many (image, text) pairs were collected in the dataset used to train CLIP?
400 million