Denoising Diffusion Probabilistic Models
Give the forward diffusion process.
Given a data point sampled from a real data distribution , let us define a forward diffusion process in which we add small amounts of Gaussian noise to the sample in steps, producing a sequence of noisy samples . The step sizes are controlled by a variance schedule
As , becomes equivalent to an isotropic Gaussian distribution.
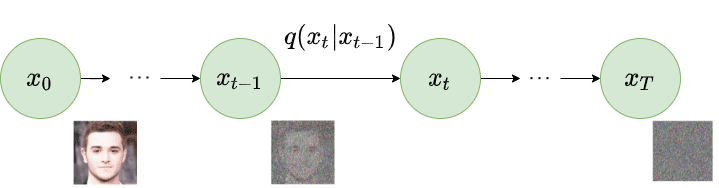 Forward diffusion process. Image modified by Ho et al. 2020
Forward diffusion process. Image modified by Ho et al. 2020
Why is the mean of the forward diffusion model scaled by , where is the variance to ?
The scaling factor is needed to avoid making the variance of grow in each step. If we would not scale it, after steps we will have a value . To force we need to scale by .
In the forward diffusion process, how can we go from to in a single step ? Recall that
Using the reparameterization trick that tells us: and (where , Reparameterization trick).
If we define and , then by recursively applying this trick:
Therefore:
Note: When merging two Gaussians and , the result is . Thus .
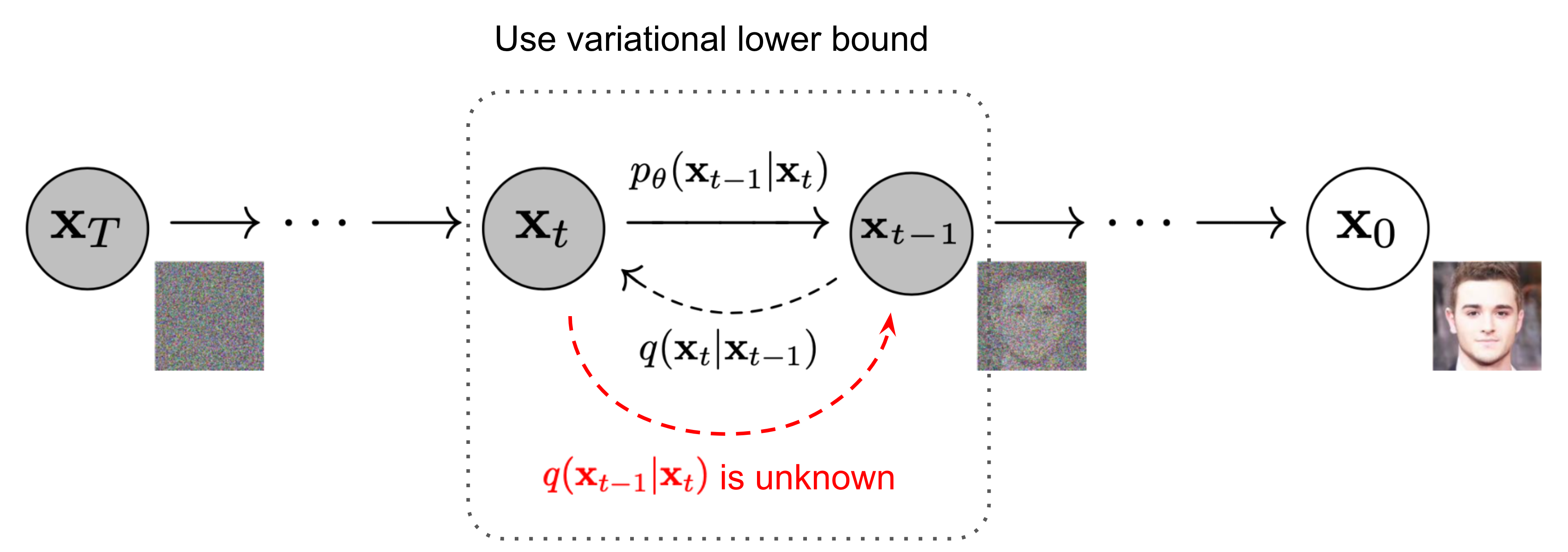
Draw the diffusion process.
Give the simplified objective funtion (loss) for diffusion models.
where is a constant not depending on .
The time-dependent loss is:
Substituting :
Give the training algorithm for Denoising Diffusion Probabilistic Models.
repeat until convergence: Take gradient descent step on
Give the inference algorithm for Denoising Diffusion Probabilistic Models.
for do: if , else return