GigaPose: Fast and Robust Novel Object Pose Estimation via One Correspondence
GigaPose uses a 3-stage 6D pose estimation approach involving: (1) object detection and segmentation, (2) coarse pose estimation and (3) refinement. On which part does GigaPose make improvements and which techniques does it use for the other parts?
GigaPose improves on (2) coarse pose estimation for (1) it uses CNOS1 and for (3) GenFlow2
1Nguyen, Van Nguyen, et al. "Cnos: A strong baseline for cad-based novel object segmentation." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023. 2Moon, Sungphill, et al. "Genflow: Generalizable recurrent flow for 6d pose refinement of novel objects." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
How does GigaPose reduce the number of templates required from a few thousands in previous methods to only 162 in GigaPose?
GigaPose estimates only 2 DOF using templates: the out-of-plane rotations (azimuth and elevation) previous methods also estimated the in-plane rotation.
The in-plane rotation is the rotation of the object that can also be performed by rotating the image. The out-of-plane rotation are the rotation about the other axis.
Give an overview of the GigaPose method.
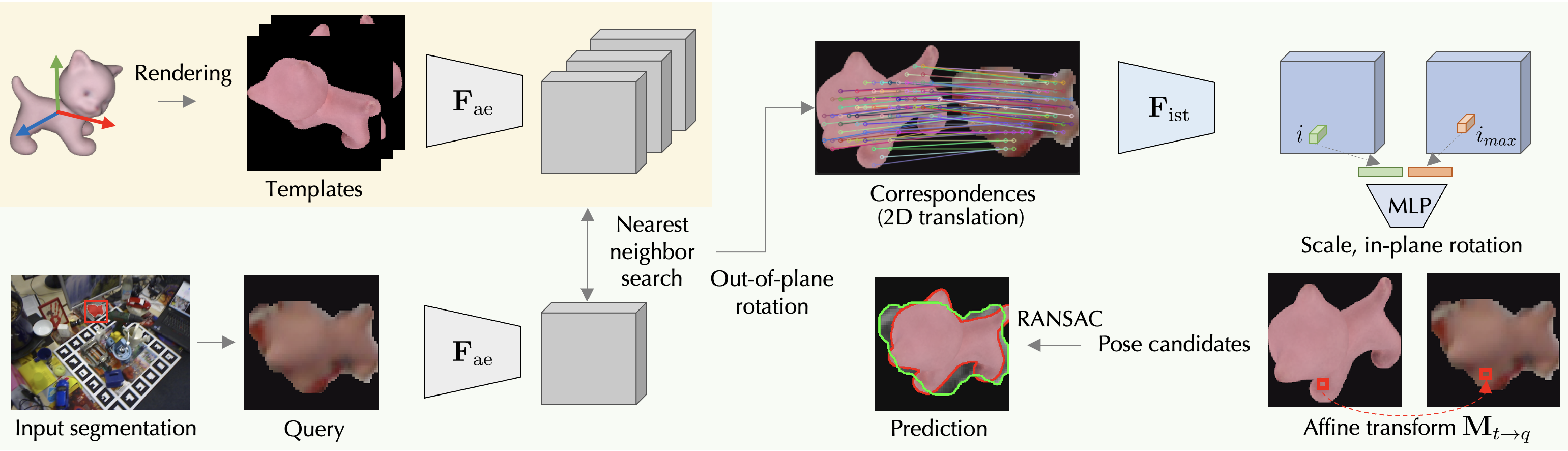 GigaPose first onboards each novel object by rendering 162 templates, spanning the spectrum of out-of-plane rotations. For each template they then extract dense features using . At runtime, the query image segmented with CNOS, is processed
by masking the background, cropping on the segment, adding padding then resizing, and features are extracted with .
The nearest template to the segment is retrieved using a patch-based similarity metric.
The 2D scale and** in-plane rotation** are computed from a single 2D-2D correspondence using and 2 MLPs.
The 2D position of the correspondences also gives us the 2D translation which is used with 2D scale, in-plane rotation to create the affine transformation , mapping the nearest template to the query image. This gives the complete 6D object pose from a single correspondence. RANSAC is used to robustly find the best pose candidate.
GigaPose first onboards each novel object by rendering 162 templates, spanning the spectrum of out-of-plane rotations. For each template they then extract dense features using . At runtime, the query image segmented with CNOS, is processed
by masking the background, cropping on the segment, adding padding then resizing, and features are extracted with .
The nearest template to the segment is retrieved using a patch-based similarity metric.
The 2D scale and** in-plane rotation** are computed from a single 2D-2D correspondence using and 2 MLPs.
The 2D position of the correspondences also gives us the 2D translation which is used with 2D scale, in-plane rotation to create the affine transformation , mapping the nearest template to the query image. This gives the complete 6D object pose from a single correspondence. RANSAC is used to robustly find the best pose candidate.