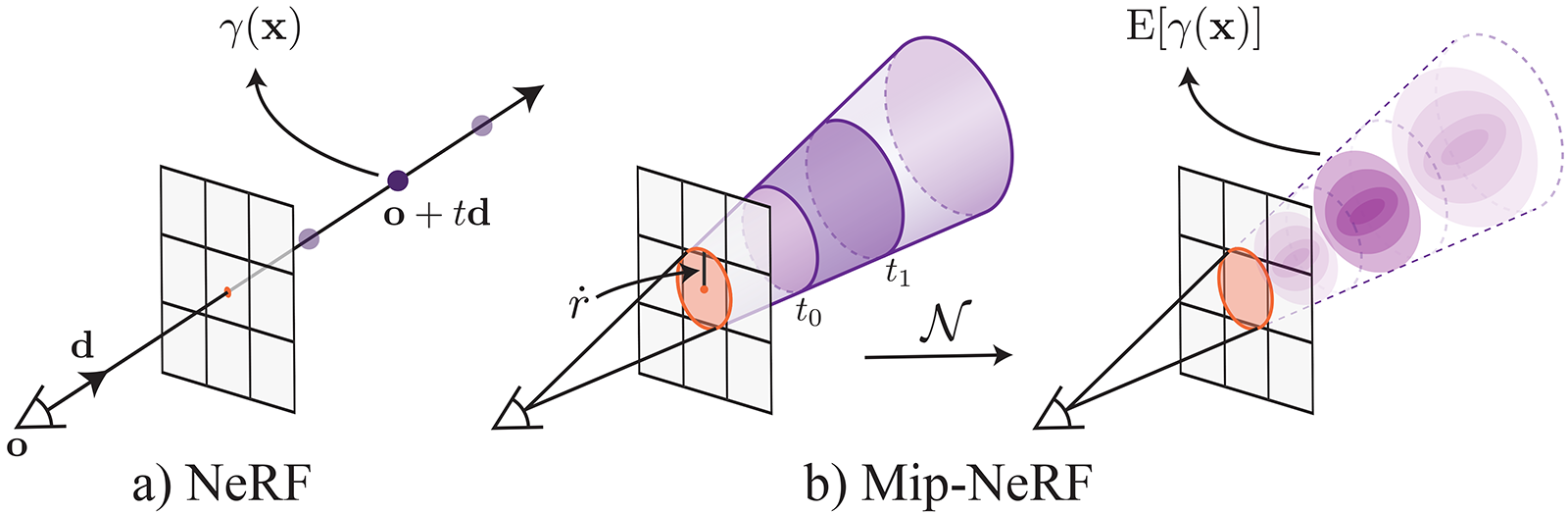
The original NeRF's rendering procedure can lead to aliasing artifacts when rendering content from multiple resolutions (e.g. zoomed in or out).
Example: Nerf (left) vs Mip-NeRF (right):
How does Mip-NeRF extend NeRF's representation?
Mip-NeRF extends NeRF to represent the scene at a continuously-valued scale, By efficiently rendering anti-aliased conical frustums instead of rays.
In Mip-NeRFhow are the conical frustrums modelled such that they can be efficiently used in NeRFs?
The conical frustrums are approximated with multivariate Gaussians.
These gaussians are fully characterized by the mean distance along the ray μt, the variance along the ray σt2 and the variance perpendicular to the ray σr2.
μt=tμ+3tμ2+tδ22tμtδ2σt2=3tδ2−15(3tμ2+tδ2)24tδ4(12tμ2−tδ2)σr2=r2(4tμ2+125tδ2−15(3tμ2+tδ2)4tδ4)with tμ=(tstart+tend)/2 and tδ=(tend+tstart)/2 and the radius r the width of the pixel in world coordinates scaled by 2/12.
Applying this to a ray gives the final guassian characteristics:
μ=o+μtd,Σ=σt2(dd⊤)+σr2(I−∣∣d∣∣22ddtop)
See paper appendix for full derivation of the above formulas.
How are the multivariate Gaussians in Mip-NeRF converted to inputs for the NeRF?
The multivariate Gaussians are transformed to integrated positional encodings (IPE).
This is the expected value of the positional encodings of samples from mulitvariate Gaussian.
γ(μ,Σ)=Ex∼N(μγ,Σγ)[γ(x)]
Machine Learning Research
Flashcards is a collection of flashcards associated with scientific
research papers in the field of machine learning. Best used with Anki or Obsidian.
Edit MLRF on GitHub.

 These gaussians are fully characterized by the mean distance along the ray , the variance along the ray and the variance perpendicular to the ray .
with and and the radius the width of the pixel in world coordinates scaled by .
Applying this to a ray gives the final guassian characteristics:
These gaussians are fully characterized by the mean distance along the ray , the variance along the ray and the variance perpendicular to the ray .
with and and the radius the width of the pixel in world coordinates scaled by .
Applying this to a ray gives the final guassian characteristics: