MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
What is the computational cost of a standard convolution with input , output and kernel size ?
What is the computational cost of a depthwise separabale convolution with input , output and kernel size ?
How much reduction in computation do you get by replacing standard convolutions with depthwise separable convolutions?
Computational cost standard convolution:
Computational cost depthwise separable convolution:
with input , output and kernel size
Reduction:
MobileNet uses depthwise separable convolutions which uses between 8 to 9 times less computation than standard convolutions.
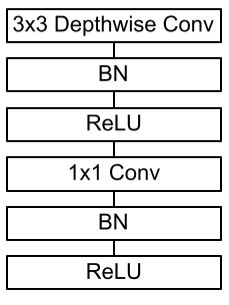
With what does MobileNet replace the standard convolutional layer with batchnorm and ReLU?
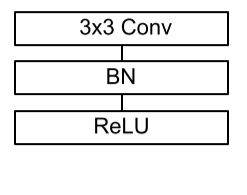
With a Depthwise Separable convolutions with Depthwise and Pointwise layers followed by batchnorm and ReLU.
Which two additional hyperparameters are introduced in **MobileNet **to construct scaled versions of the standard architecture?
Width multiplier: The role of the width multiplier is to thin a network uniformly at each layer. For a given layer and width multiplier , the number of input channels becomes and the number of output channels becomes .
Width multiplier has the effect of reducing computational cost and the number of parameters quadratically by roughly .
Resolution multiplier:
The resolution multiplier is applied to the input image and the internal representation of every layer is subsequently reduced by the same multiplier. In practice we implicitly set by setting the input resolution.
Resolution multiplier has the effect of reducing computational cost by .* *
How many multiply-adds and parameters does the default MobileNetV1 have? And how much accuracy does it get on ImageNet?
569M MAdds and 4.2M parameters with an accuracy of 70.6% on ImageNet.