Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Draw an overview of the Sparsely Gated Mixture of Experts (MoE) layer.
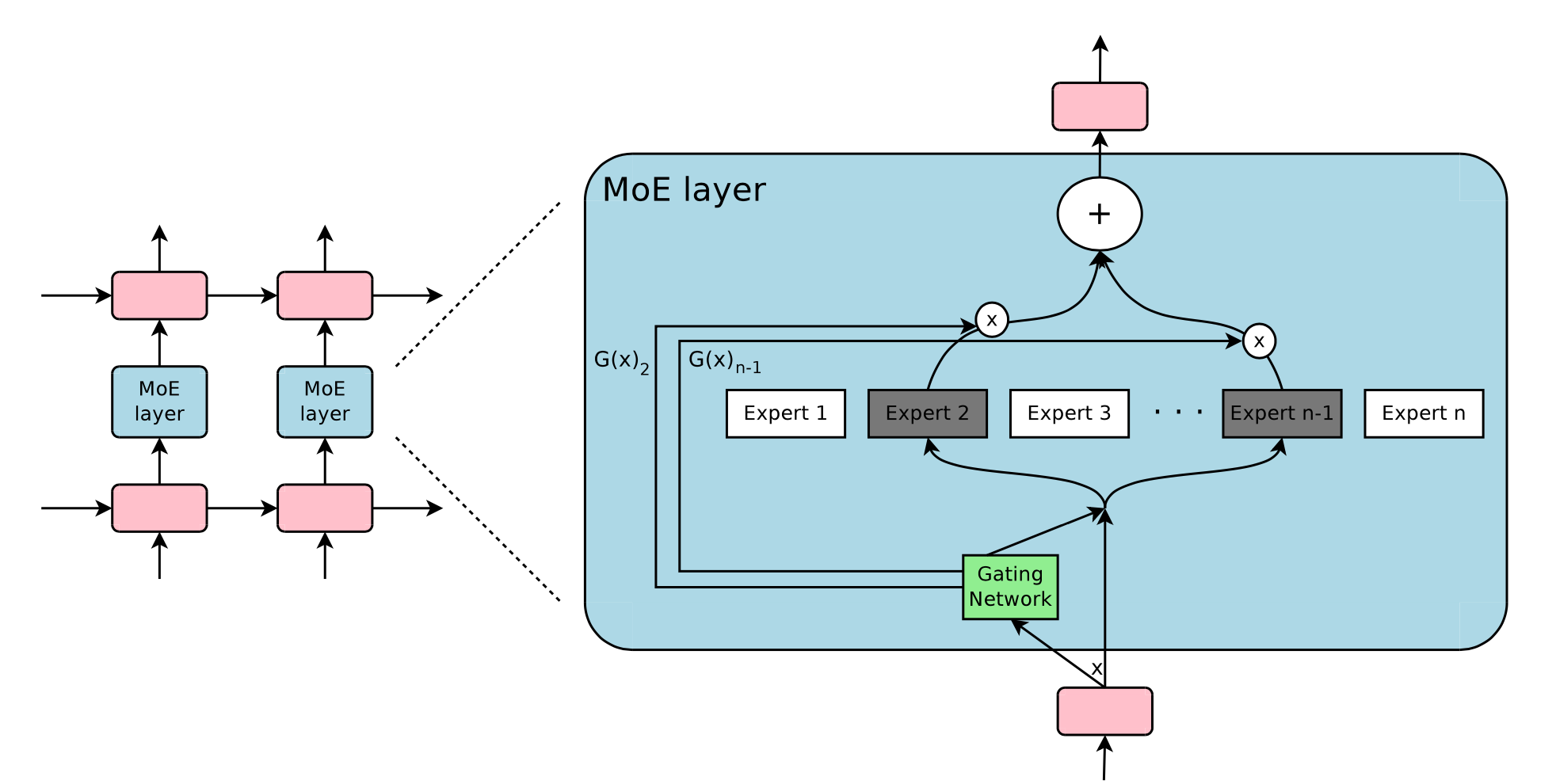 The Mixture-of-Experts layer consists of experts (simple feed forward layers in the original paper) and a gating network whose output is a sparse dimensional vector.
The Mixture-of-Experts layer consists of experts (simple feed forward layers in the original paper) and a gating network whose output is a sparse dimensional vector.
Let us denote by and the output of the gating network and the output of the -th expert network for a given input . The output of the MoE module can be written as follows: We save computation based on the sparsity of the output of .
Give the structure of the gating network that is used in Sparsely Gated MoE.
A simple choice of is to multiply the input with a trainable weight matrix and then apply a : .
However we want a sparsely gated MoE where we only evaluate the top- experts. The sparsity serves to save computations. Thus the MoE layer only keeps the top- values: where the keep-top- operation is:
Here is a linear layer with added tunable Gaussian noise such that each expert sees enough training data and we avoid favouring only a few experts for all inputs:
What is the shrinking batch problem in MoEs?
If a MoE uses only out of experts, then for a batch of size , each export only receive approximately samples.
Through data and model parallelism this problem can be negated.
How does the Sparsely-Gated MoE paper avoid the gating network to always favor the same few strong experts?
They soft constrain the learning with an additional importance loss that encourages all experts to have equal importance. Where importance is defined as: The importance loss is then defined as the coefficient of variation of the batchwise average importance per expert: Where the coefficient of variation CV is defined as the ratio of the standard deviation to the mean , .
In the Sparsely gated MoE paper what is the load loss and what does it encourage?
The load loss encourages equal load per expert. It uses a smooth estimator of examples per expert and minimizes:
For the full calculation of the load value, check the original paper.