OpenVLA: An Open-Source Vision-Language-Action Model
Describe the OpenVLA architecture (inputs, outputs, components).
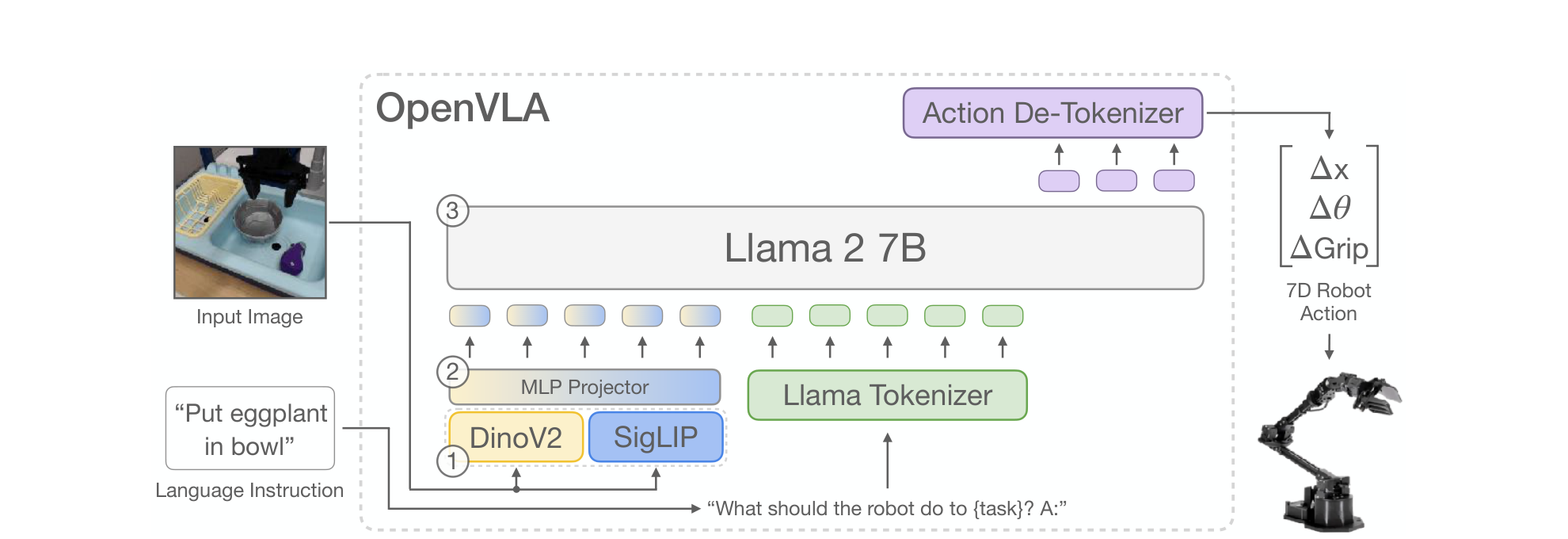
OpenVLA is a 7B-parameter VLA built on the Prismatic-7B VLM. Given a single RGB image and a natural-language instruction ("What should the robot do to {task}? A:"), it autoregressively emits action tokens that are de-tokenized into a 7-DoF end-effector action (, , gripper).
Three components:
- Visual encoder (~600M): a fused DINOv2 + SigLIP stack , image patches go through both encoders separately and the per-patch features are concatenated channel-wise.
- MLP projector (2 layers): maps fused visual features into the LLM's input embedding space.
- LLM backbone: Llama 2 7B generates action tokens via standard next-token prediction.
How does OpenVLA turn continuous robot actions into tokens the Llama 2 backbone can predict?
Each of the 7 action dimensions is uniformly discretized into 256 bins between the 1st and 99th quantile of the training-data action values (quantiles, not min/max, so outliers don't blow up the bin width and reduce effective granularity).
The Llama tokenizer only reserves 100 special-token slots during fine-tuning, which is too few for 256 action tokens. Following RT-2, OpenVLA overwrites the 256 least-used tokens in the Llama vocabulary with the action tokens.
Training is standard next-token prediction with cross-entropy loss evaluated only on the action tokens.
Why does OpenVLA use a fused DINOv2 + SigLIP visual encoder instead of CLIP- or SigLIP-only?
The dual encoder inherits complementary features: SigLIP contributes higher-level semantics (good for language grounding) while DINOv2 contributes low-level spatial detail (good for precise localization).
Karamcheti et al. (Prismatic) showed this fused encoder improves spatial reasoning over CLIP/SigLIP-only encoders, and the OpenVLA authors found Prismatic outperformed LLaVA-based and IDEFICS-based VLA backbones by ~10% absolute on multi-object language-grounding tasks — they attribute this to the fused encoder.
List the four key VLA design decisions the OpenVLA authors call out (and the surprising findings).
- VLM backbone: Prismatic-7B beat IDEFICS-1 and LLaVA; Prismatic > LLaVA by ~10% absolute, mostly thanks to fused DINOv2+SigLIP.
- Image resolution: 224×224 vs. 384×384 made no difference in VLA success rate, but 384 was 3× more expensive so they kept 224. (Counter-intuitive: on VLM benchmarks, more resolution usually helps.)
- Fine-tune the vision encoder (don't freeze it). The opposite of standard VLM practice: they hypothesize pretrained features lack the fine-grained spatial detail needed for precise control.
- Many epochs. Unlike LLM/VLM training (1–2 epochs), VLA training keeps improving until action-token accuracy >95%. Final run was 27 epochs. Constant LR of 2e-5, no warmup.
How does OpenVLA differ from RT-2-X?
Both are VLAs trained on Open X-Embodiment, but:
| RT-2-X | OpenVLA | |
|---|---|---|
| Params | 55B | 7B (~8× smaller) |
| Backbone | Closed (PaLI-X / PaLM-E) | Open (Prismatic = Llama 2 + DINOv2 + SigLIP) |
| Task success vs. RT-2-X | / | +16.5% absolute across 29 tasks |
| Fine-tuning | Not investigated / API-gated | Full FT, LoRA, and quantization all studied |
| Visual encoder | Single ViT | Fused DINOv2 + SigLIP |
OpenVLA is also the first open-source generalist VLA, exposing weights, code, and data mixture to the community.
What does the OpenVLA training setup (data, compute) look like?
- Data: 970k robot demonstrations curated from the Open X-Embodiment dataset (>70 datasets, ~2M trajectories raw). Curated to (a) only manipulation datasets with at least one 3rd-person camera and single-arm end-effector control, and (b) Octo's data-mixture weights (down-weight low-diversity datasets, up-weight diverse ones).
- Compute: 64× A100 GPUs for 14 days = 21,500 A100-hours, batch size 2048, fixed LR 2e-5, 27 epochs.
- Inference: 15 GB GPU memory in bfloat16; runs at ~6 Hz on an A100.
How effective is LoRA fine-tuning for OpenVLA, and how does it compare to alternatives?
The authors compare 5 fine-tuning strategies (Franka-Tabletop tasks):
| Strategy | Success | Train params |
|---|---|---|
| Full FT | 69.7% | 7,188M (163 GB VRAM) |
| Last layer only | 30.3% | 465M |
| Frozen vision | 47.0% | 6,760M |
| Sandwich (vision + embed + last layer) | 62.1% | 914M |
| LoRA (r=32 or 64) | 68.2% | 97.6M (1.4%) |
Takeaways:
- Freezing the vision encoder hurts a lot: visual features must adapt to the new scene.
- LoRA matches full FT while training only 1.4% of parameters and fitting on a single A100 (10–15 hr per task vs. 8× A100s for full FT — 8× compute reduction).
- LoRA rank had negligible effect; default r=32.
What are the main limitations of OpenVLA?
- Single-image input only: no multi-camera, proprioception, or observation history. Real robot setups are heterogeneous; supporting interleaved-vision-text VLM backbones is suggested as future work.
- Inference throughput: 6 Hz on an A100 is fine for the 5–15 Hz tasks studied, but inadequate for high-frequency setups like ALOHA (50 Hz) or bimanual dexterous tasks. Action chunking or speculative decoding are mentioned as remedies.
- Reliability ceiling: typically <90% success rate on the tested tasks.
- Underexplored design space: effect of base VLM size, value of co-training on web vision-language data (which RT-2 used but OpenVLA does not), best visual features for VLAs, etc.