RT-1: Robotics Transformer for Real-World Control at Scale
Draw and describe the RT-1 architecture.
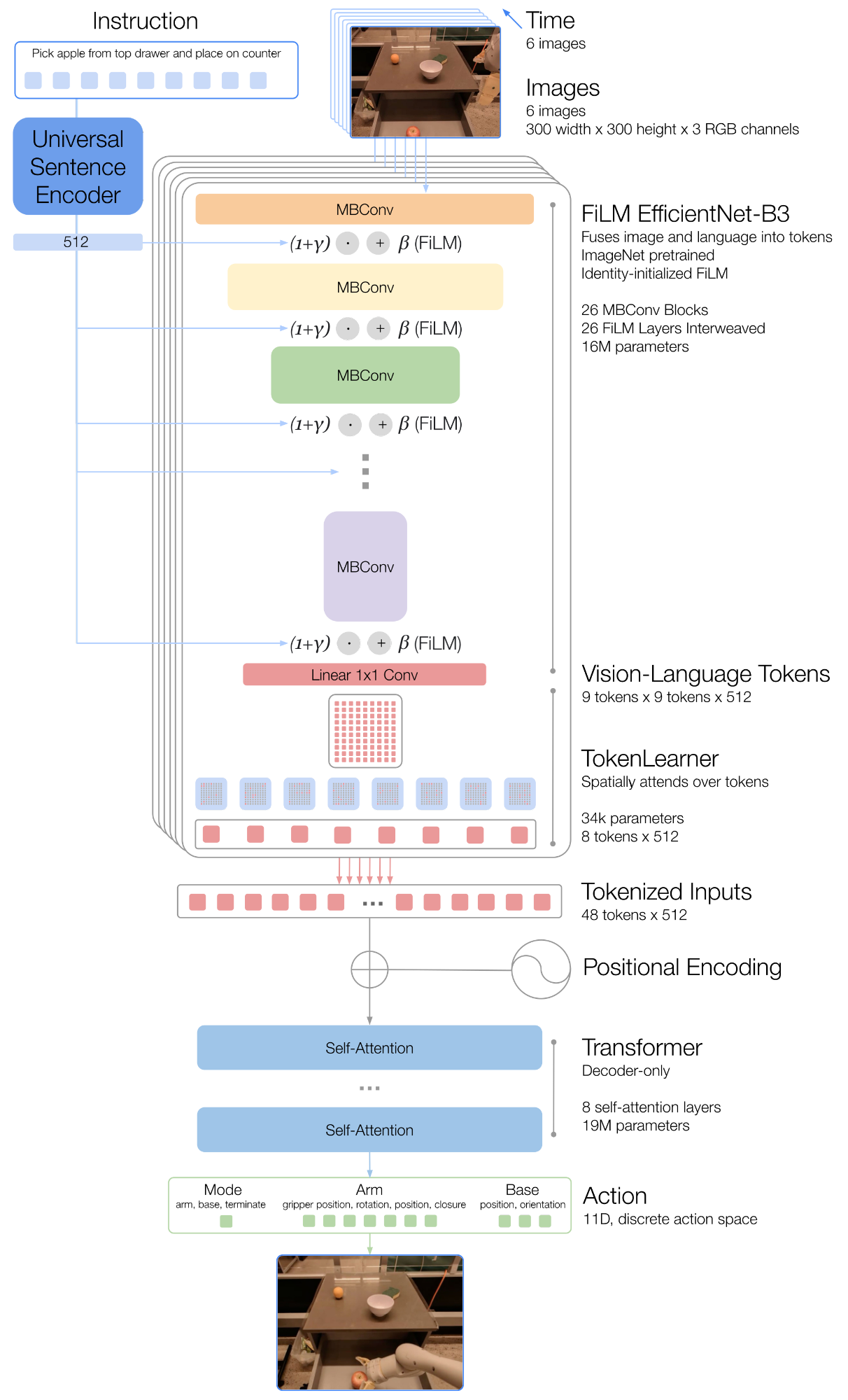
- Instruction: natural language text that is embedded via Universal Sentence Encoder (USE).
- 6 history images (300×300) passed through EfficientNet-B3, conditioned on the instruction embedding via FiLM layers (identity-initialized). Output: 81 vision-language tokens per image.
- TokenLearner compresses 81 -> 8 tokens per image (soft-selecting the informative ones).
- 8 tokens 6 images = 48 tokens (+ position encodings) are fed into a decoder-only Transformer (8 self-attention layers, 19M params).
- The Transformer outputs discretized action tokens.
What are the input and output of RT-1?
Input: a history of 6 RGB images (300×300) and a natural language instruction.
Output: an 11-dimensional action, consisting of:
- 7 arm dimensions:
- 3 base dimensions:
- 1 mode dimension: switch between {control arm, control base, terminate episode}
Each action dimension is discretized into 256 bins.
Which loss is used to train RT-1?
RT-1 is trained with a standard categorical cross-entropy loss with causal masking.
How does RT-1 tokenize actions, and which loss is used to train it?
Each of the 11 action dimensions is uniformly discretized into 256 bins, turning action prediction into classification over tokens.
RT-1 is trained with behavioral cloning using a standard categorical cross-entropy objective and causal masking (following prior Transformer-based controllers like Gato).
What role does FiLM play in the RT-1 image tokenizer, and why is it identity-initialized?
FiLM layers are inserted into the pretrained EfficientNet-B3 to condition the image encoder on the language instruction (from USE), so that task-relevant image features are extracted early in the network.
Normally, inserting FiLM layers into a pretrained network would disrupt the intermediate activations and destroy the benefit of the pretrained weights. To prevent this, the dense layers producing the FiLM affine transform ( and ) are initialized to zero, so the FiLM layers initially act as the identity and the pretrained EfficientNet's function is preserved at the start of training.
What is the role of TokenLearner in RT-1?
TokenLearner is an element-wise attention module that learns to map a large number of tokens to a much smaller number of tokens by soft-selecting the most informative combinations.
In RT-1, it reduces the 81 vision-language tokens output by FiLM-EfficientNet (per image) down to just 8 tokens per image, which are then fed into the Transformer backbone. This is a key component for meeting the real-time inference budget.
Using TokenLearner gives a ~2.4× inference speedup. (An additional 1.7× speedup comes from caching and reusing tokens across overlapping image-history windows.)
How many parameters does RT-1 have, and how are they distributed?
~35M parameters in total:
- ~16M: FiLM EfficientNet-B3 image + instruction tokenizer (26 MBConv + FiLM layers, outputs 81 vision-language tokens).
- ~19M: decoder-only Transformer backbone (8 self-attention layers) that produces the action tokens.
How does RT-1 differ architecturally from Gato as a robot policy?
Gato is also based on a transformer architecture, but varies in tmulple aspects:
- Language fusion: RT-1 uses early language fusion via FiLM-conditioned EfficientNet, so image tokens are already task-aware. Gato computes image patch tokens without any notion of language.
- Image tokens: RT-1 uses a global, FiLM-conditioned CNN feature map; Gato embeds each image patch separately.
- Language embedding: RT-1 uses a pretrained USE embedding. Gato does not use a pretrained text embedding.
- Inference-time design: RT-1 adds TokenLearner and removes auto-regressive action generation to hit real-time control rates; Gato does not.