RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Give a high-level overview of RT-2.
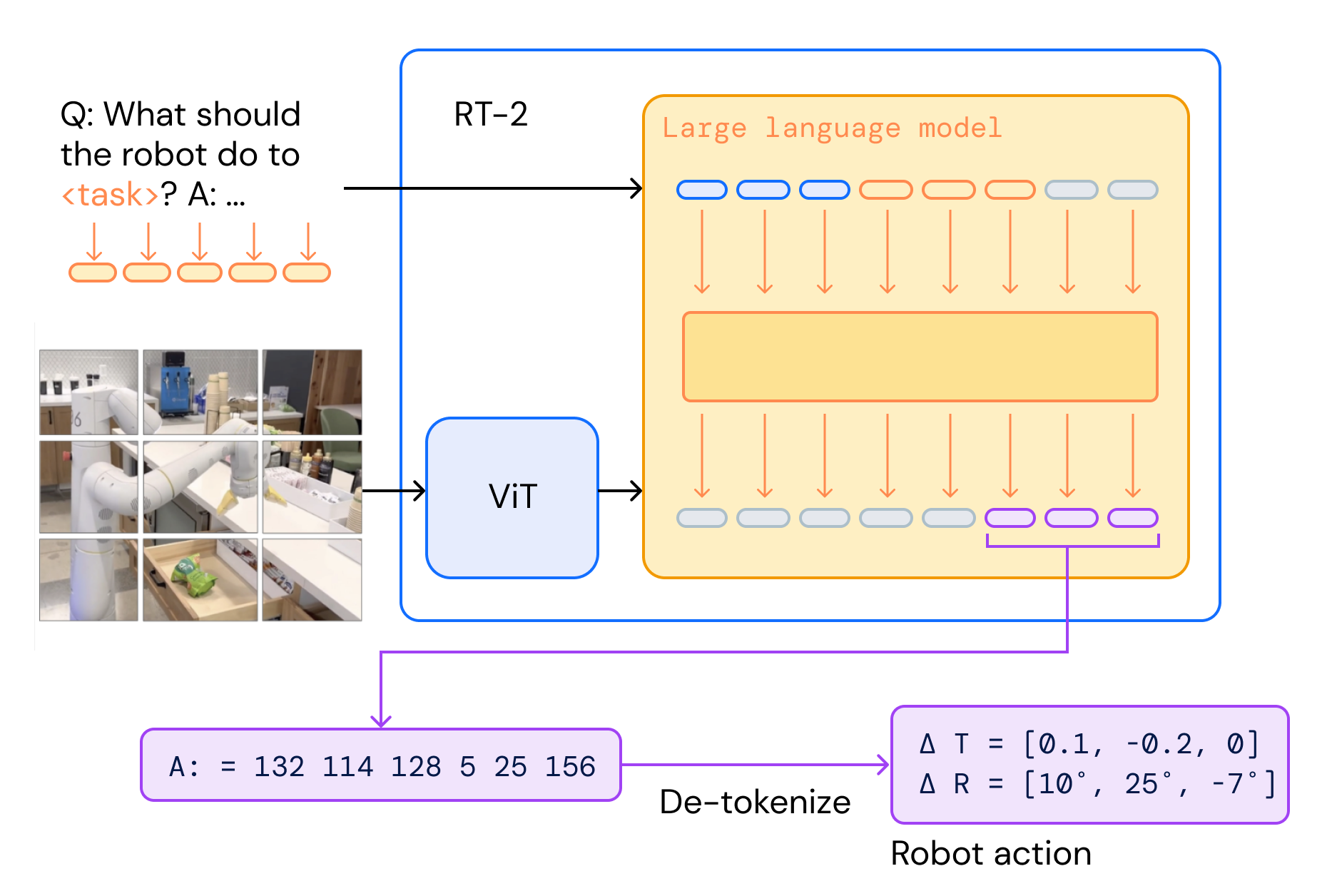
RT-2 is a vision-language-action (VLA) model: a pretrained vision-language model (PaLI-X or PaLM-E) that is co-fine-tuned on web-scale VQA/caption data together with robot trajectories, where robot actions are tokenized as text and emitted exactly like any other output tokens.
At deploy time the same VLM receives a robot camera image + task instruction in a VQA-style prompt and generates an action string; its output is de-tokenized into a 6-DoF end-effector command and executed on the robot in a closed loop.
What are the inputs and outputs of RT-2, and what does a training example look like?
Input: a single robot camera image + a natural-language instruction, formatted as a standard VQA prompt:
Q: what action should the robot take to [task instruction]? A:
Output: a single string of action tokens (concatenated with spaces):
terminate Δpos_x Δpos_y Δpos_z Δrot_x Δrot_y Δrot_z gripper_extension
A concrete instantiation is e.g. "1 128 91 241 5 101 127". The VLM generates this string autoregressively; it is then de-tokenized back into the 11-DoF (6-DoF end-effector Δ + gripper + discrete termination) action from RT-1.
How does RT-2 tokenize robot actions so they can be emitted by a pretrained VLM?
RT-2 reuses the RT-1 discretization.
The action space consist of 6-DOF postion of the end-effector, the gripper extension and a special discrete termination token. Each continuous action dimension is uniformly binned into 256 bins, giving an action vector of 8 integers (7 continuous + 1 discrete termination).
To deiscretize this, the VLM assign 256 of its existing text tokens to serve as action tokens. This depends on the backbone:
- PaLI-X: integers 0–999 each already have their own unique token, so action bin simply reuses the token for the integer .
- PaLM-E: has no such convenient numeric vocabulary, so the 256 least-frequently-used tokens are overwritten to represent the action vocabulary (i.e. a form of symbol tuning (Wei et al., 2023)).
The resulting target is one space-separated string, letting the VLM train with an unmodified next-token-prediction objective.
What is co-fine-tuning in RT-2, and why does it matter?
Instead of fine-tuning the VLM on robot trajectories alone, RT-2 co-fine-tunes on a mixture of the original web-scale VLM data (VQA, captioning, interleaved image/text) and robot demonstrations, up-weighting the robot data so it dominates each batch (e.g. ~66% of the mixture for RT-2-PaLM-E-12B and 50% for RT-2-PaLI-X).
The paper shows that co-fine-tuning yields better generalization than plain fine-tuning regardless of model size.
What is the output constraint applied to RT-2 at inference, and why is it needed?
A vanilla VLM can emit any token in its vocabulary, but a robot can only execute valid action tokens. When RT-2 is prompted with a robot-action task, decoding is restricted to sample only from the 256 action tokens, guaranteeing that every generated string de-tokenizes into a legal action.
On non-robot prompts (VQA, captioning) the full natural-language vocabulary is still allowed, so the same weights retain their general VLM behavior.
How does RT-2 relate to, and differ from, RT-1 and PaLM-E?
- vs. RT-1 (35M, trained from scratch):
- Shares the action discretization (256 bins, same 7+1 action dims) and the behavioral-cloning objective.
- Replaces the bespoke FiLM-EfficientNet + TokenLearner + small Transformer with a single pretrained VLM and treats actions as just another text output, no task-specific vision stack.
- vs. PaLM-E (embodied multimodal LLM):
- PaLM-E outputs text-level high-level plans that a separate low-level policy (often RT-1) must execute.
- RT-2 is the low-level policy: the same VLM generates end-effector deltas directly, closing the loop without a downstream controller.
The common thread: inherit web-scale semantic knowledge from a VLM, then make it speak "action" as another language.
What limitations of RT-2 do the authors call out?
- No new motor skills from web data. Co-fine-tuning on VQA/caption data improves generalization (new objects, backgrounds, symbols, reasoning) but the robot's physical skill repertoire is still bounded by the skills demonstrated in the robot dataset — the VLM cannot invent motions it never saw.
- Inference cost. Serving 55B parameters in a control loop requires a multi-TPU cloud backend, capping control rates at 1–3 Hz (55B) / ~5 Hz (5B). For tasks demanding high-frequency control, VLM inference is the dominant bottleneck.