A Simple Framework for Contrastive Learning of Visual Representations
Give schematic of the contrastive learning framework used in SimCLR.
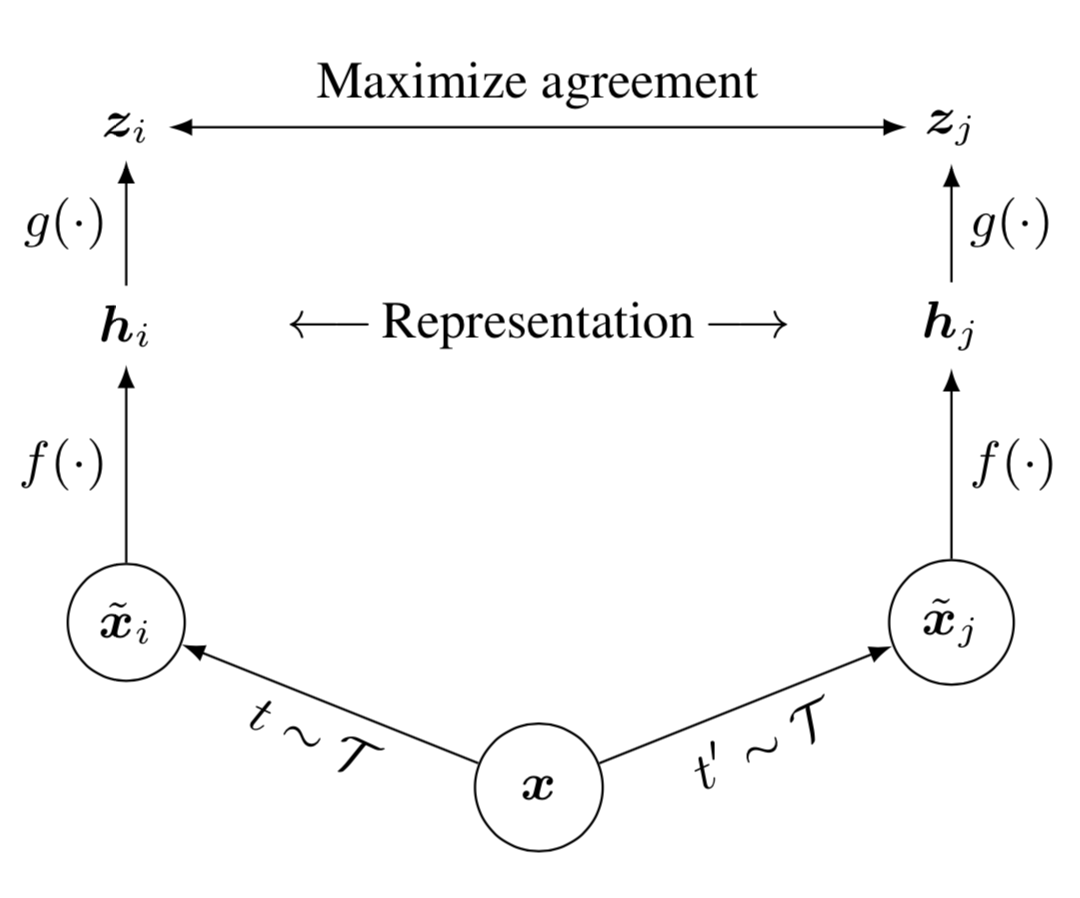
Framework for contrastive learning of visual representations. Two separate data augmentations operators are sampled from the same family of augmentations () and applied to each data example to obtain two correlated views. A base encoder network and a projection head are trained to maximize agreement using a contrastive loss. After training is completed, throw away the projection head and use encoder and representation for downstream tasks.
Which similarity metric is used in SimCLR?
Cosine similarity This can be represented by using a dot product and scaling by the magnitudes.
Which loss function is used in SimCLR?
The loss function for a positive pair of examples is defined as: where is the similarity metric (usually cosine similarity). The final loss is computed across all positive pairs, both and .
This loss can be called the normalized temperature-scaled cross entropy loss (NT-Xent). It has been used in prior work.
Give the training algorithm for SimCLR.
input: batch size , temperature constant , encoder , projection head , augmentation family . for sampled minibatch do: for all do: sample two augmentation functions , for all and do: define update networks and to minimize return encoder and throw away
In contrastive frameworks such as SimCLR, why is the similarity optimized on a separate projection head ?
It likely due to the fact that the contrastive representation needs to be invariant to many data transformations, as such information such as color is removed in this representation while this may be useful for downstream tasks. By adding an additional projection head, can remove information that may be useful for downstream tasks but needs to be removed in order to maximize the contrastive similarity.However all of this is found empirically.