Templates for 3D Object Pose Estimation Revisited: Generalization to New Objects and Robustness to Occlusions
How does the paper Templates for 3D Object Pose Estimation Revisited: Generalization to New Objects and Robustness to Occlusions match a real image to the most similar template?
Query image (which is already a cropped image with only one object) is passed through a local feature extraction network resulting in local features , where indicates the index of the 2D feature grid. This network is trained in a contrastive manner to maximize the similarity of a real image and the closest rendered template. The most similar template is the one with the highest similarity score: where is a 2D binary visibility mask for template , is a local similarity metric such as the cosine similarity, , with a threshold applied to the similarity to turn off the occluded local features.
Which loss function is used to the train the local feature network in Templates for 3D Object Pose Estimation Revisited: Generalization to New Objects and Robustness to Occlusions?
The InfoNCE loss function: Previous papers used the Triplet loss function but this performs worse.
This loss is also known as the NT-Xent loss in the SimCLR paper.
How is the local feature network trained in Templates for 3D Object Pose Estimation Revisited: Generalization to New Objects and Robustness to Occlusions?
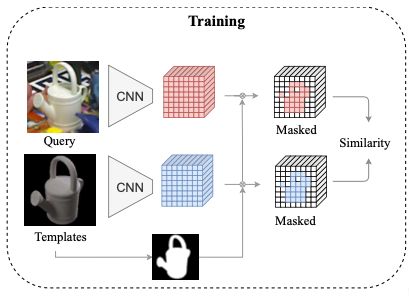 In each training iteration, positive pairs, where a pair is a real image and a synthetic render of the same object with at most 5° difference in viewpoint angle. All the pairs composed by a real image and a synthetic render of a different object or a dissimilar pose are defined as negative pairs.
A convolutional neural network that outputs a 2D local feature representation is trained using the contrastive learning loss InfoNCE.
In each training iteration, positive pairs, where a pair is a real image and a synthetic render of the same object with at most 5° difference in viewpoint angle. All the pairs composed by a real image and a synthetic render of a different object or a dissimilar pose are defined as negative pairs.
A convolutional neural network that outputs a 2D local feature representation is trained using the contrastive learning loss InfoNCE.