Universally Slimmable Networks and Improved Training Techniques
What is the main difference between the original slimmable networks paper and the universally slimmable networks paper?
The originally slimmable networks could only be slimmed to predefined widths (e.g. [0.25, 0.5, 0.75, 1.0]), the universally slimmable networks (US-Nets) extend this to networks of arbitrary width.
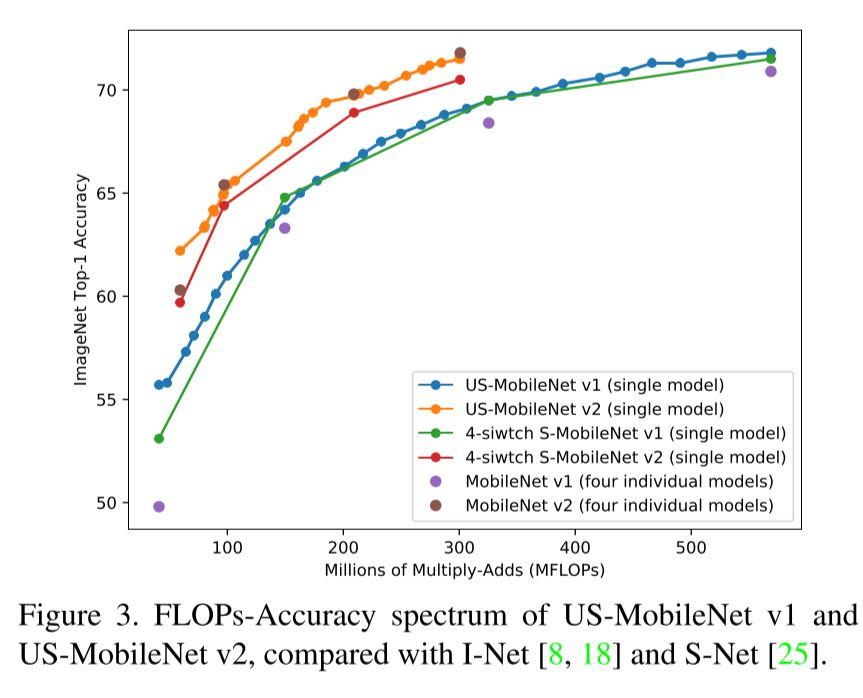
One the main issues and reason to work with predefined widths in Slimmable Networks was batch normalization, how is that solved in Universally Slimmable networks?
The batch normalization only caused issues during testing. In universally trainable networks they argue that you can just compute the batch norm statistics of an arbitrary width with a large minibatch before you start using it.
What are the main new techniques in Universally Slimmable networks?
The sandwich rule: Instead of running the model at fixed widths as in Slimmable Networks they randomly sample widths in the range and train the model with these widths along with the smallest and largest width.
Inplace distillation:
For the largest model the ground truth is used as labels but for all other models the predicted labels of this largest model is used as training label.