Auto-Encoding Variational Bayes
What is the formula for variational lower bound, or evidence lower bound (ELBO) in variational Bayesian methods?
The evidence lower bound (ELBO) is defined as The lower bound part in the name comes from the fact that the KL divergence is always non-negative and thus ELBO is the lower bound of .
Derive the ELBO loss function used for variational inference.
The goal in variational inference is to minimize with respect to .
Starting from the definition and expanding step-by-step:
Using :
Expanding the logarithm:
Using :
Therefore:
Once rearrange the left and right hand side of the equation,
The left side of the equation is exactly what we want to maximize when learning the true distributions: we want to maximize the (log-)likelihood of generating real data (that is ) and also minimize the difference between the real and estimated posterior distributions (the term works like a regularizer). Note that is fixed with respect to .
The negation of the above defines our loss function:
Which can also be written as:
Optimal parameters are found by:
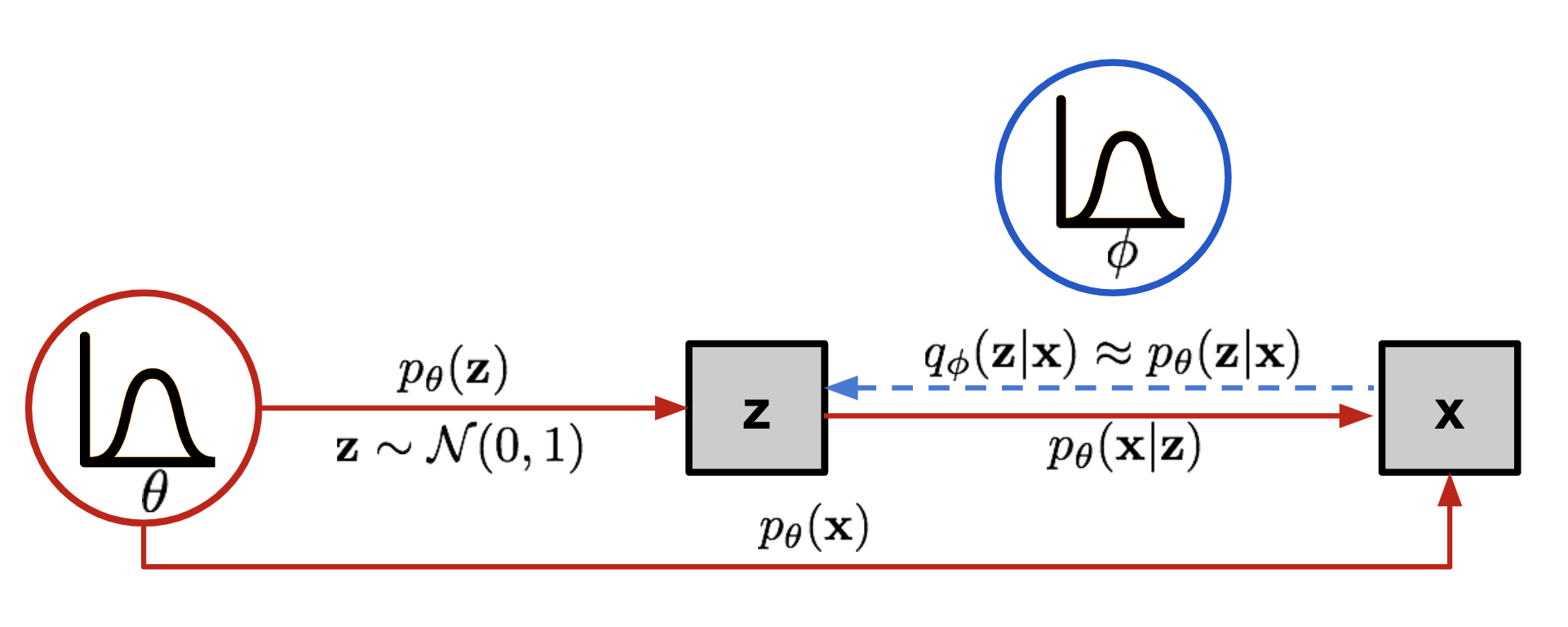 The graphical model involved in Variational Autoencoder. Solid lines denote the generative distribution and dashed lines denote the distribution to approximate the intractable posterior .
Source: https://lilianweng.github.io/posts/2018-08-12-vae/
The graphical model involved in Variational Autoencoder. Solid lines denote the generative distribution and dashed lines denote the distribution to approximate the intractable posterior .
Source: https://lilianweng.github.io/posts/2018-08-12-vae/
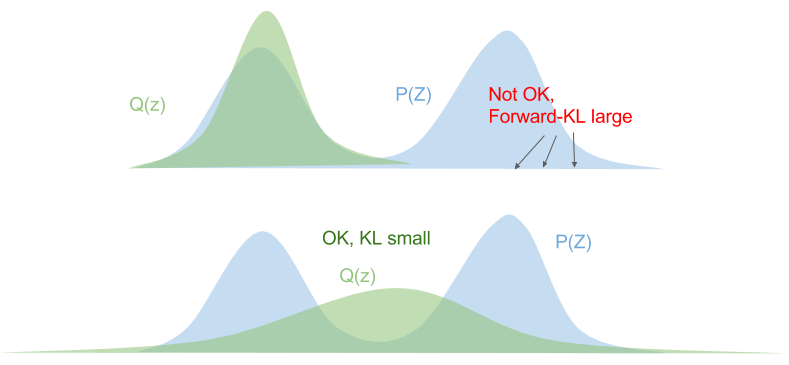
Why does ELBO use the reverse Kullback-Leibler divergence instead of the forward KL divergence ?
KL divergence is not a symmetric distance function, i.e. .
Let's consider the forward KL divergence:
This means that we need to ensure that wherever . The optimized variational distribution is known as zero-avoiding.
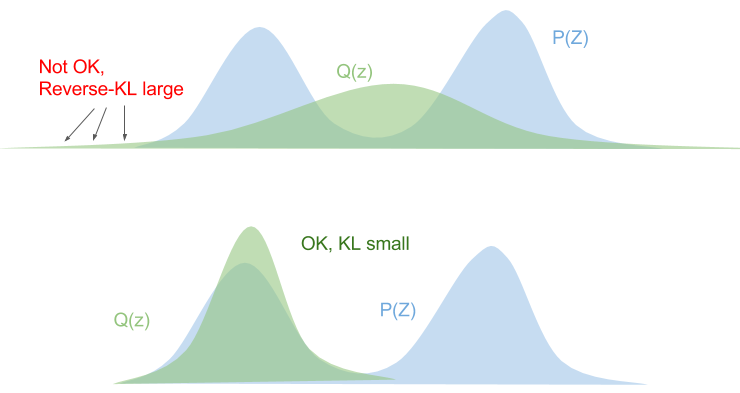
 The reversed KL divergence has the opposite behaviour.
If , we must ensure that , othewise the KL divergence blows up. This is known as zero-forcing.
The reversed KL divergence has the opposite behaviour.
If , we must ensure that , othewise the KL divergence blows up. This is known as zero-forcing.
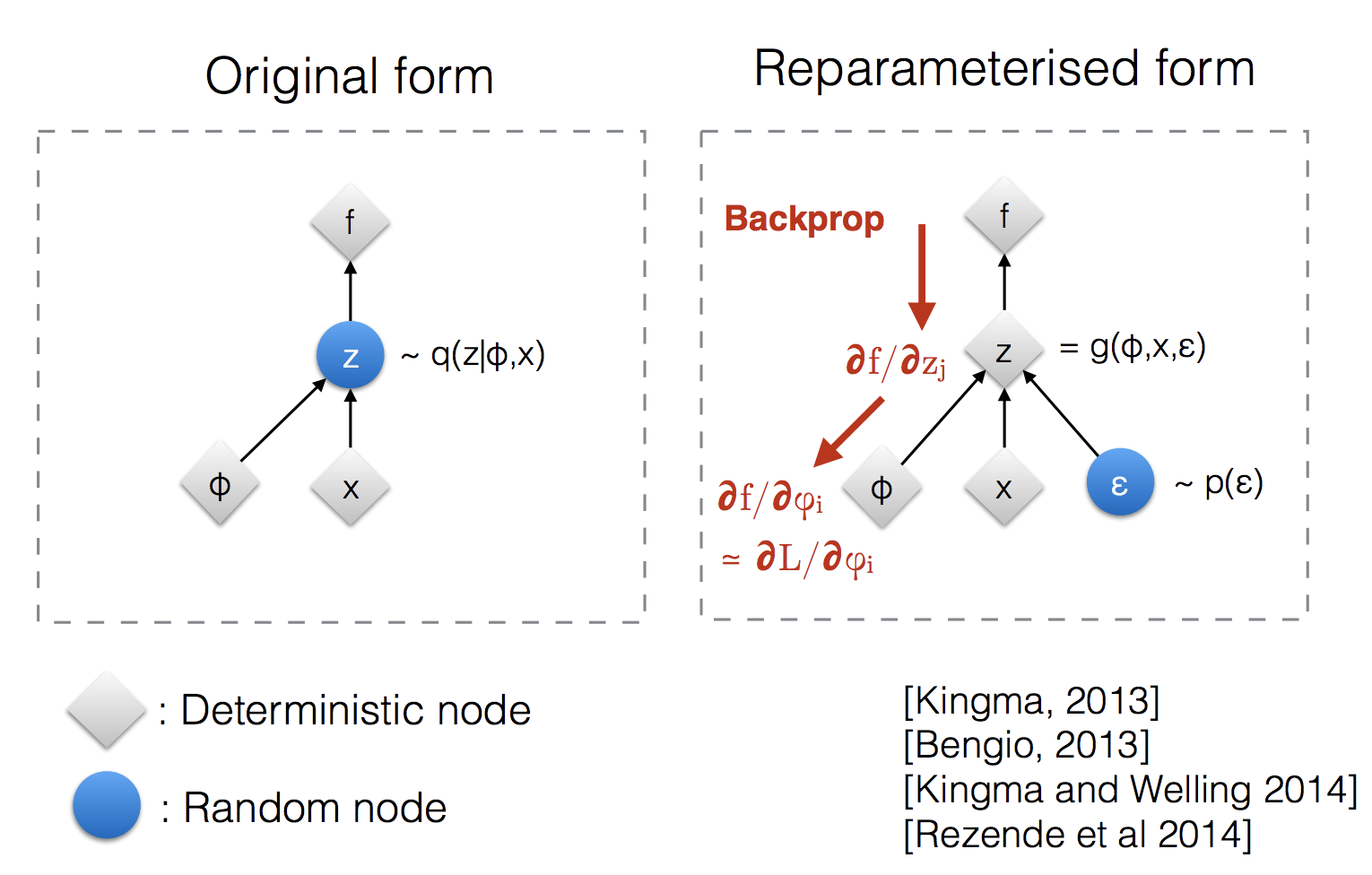
What is the reparameterization trick used in variational autoencoders?
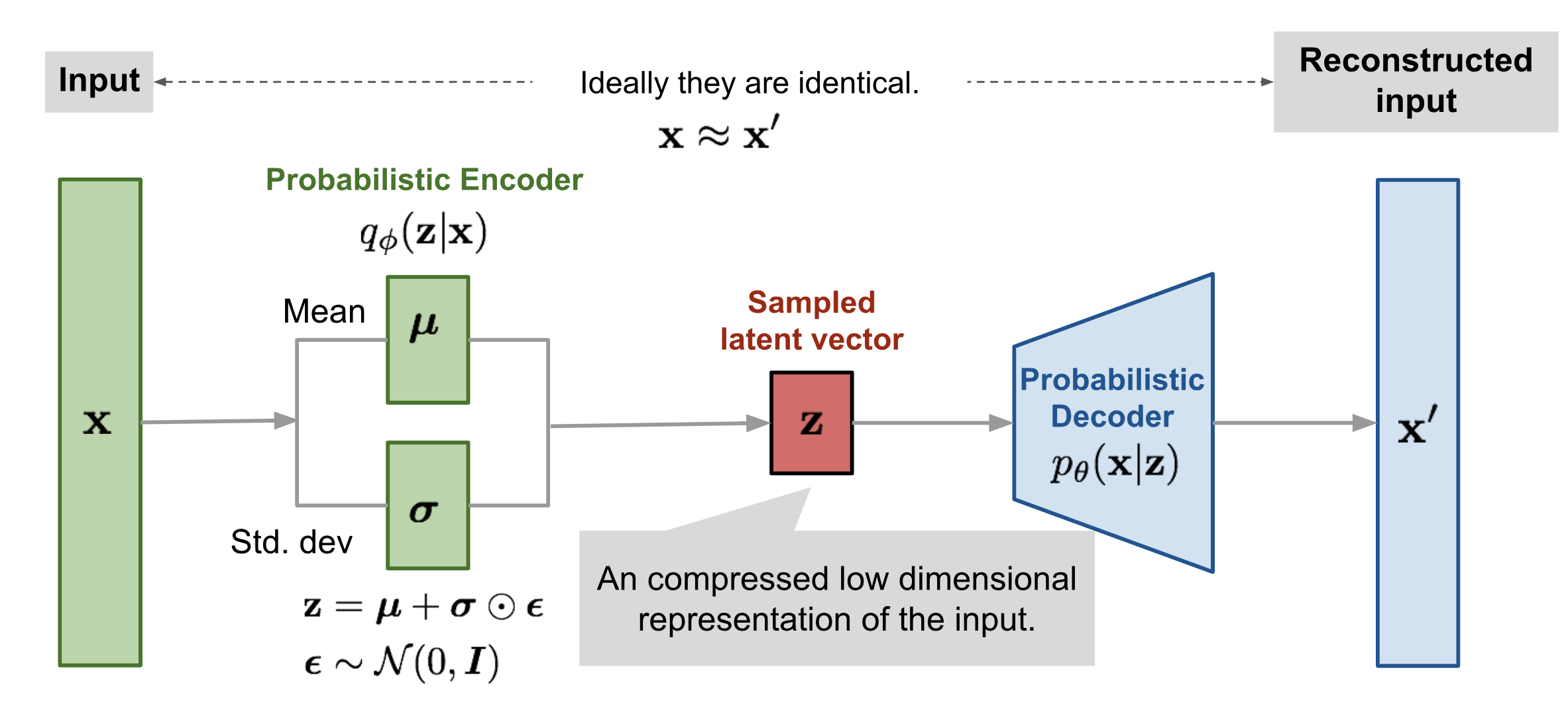
Variational autoencoders sample from . Sampling is a stochastic process and therefore we cannot backpropagate through it. To make it differentiable, the reparameterization trick is introduced. It is often possible to express the random variable as a deterministic variable , where is an auxiliary independent random variable and the transformation function converts to .
For example, a common choice of the form of is a multivariate Gaussian with a diagonal covariance structure:
Using the reparameterization trick:
Draw the architecture of a variational autoencoder (VAE).